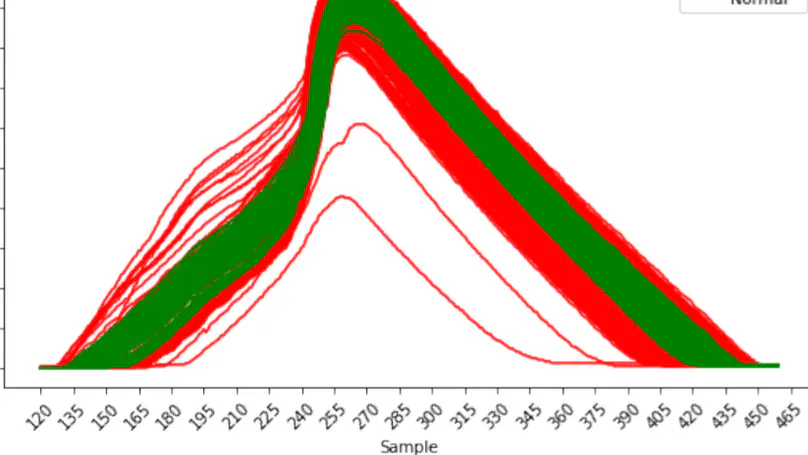
The “Institut für Werkstofftechnik und Kunststoffverarbeitung” (IWK) is a leading Swiss institute in the area of materials technology and polymers processing. One area of interest is to optimize the yield of injection molding machines. Injection molding machines are typically commissioned by an experienced operator and then run for weeks and months, where they produce millions of identical goods. To lower the amount of defective goods during this contiuous manufacturing process, it needs to be monitored at all times. Thus anomalies can be detected and corrected in a early stage. To achieve this objective, the current state-of-the-art method monitors several measurement variables during the process and stores them as persistent data in memory. Based on these measurements, manually defined features are extracted and passed into an anomaly detector. The difficulty of this approach on the one hand is the accessability of the data, as there is no unified interface across the industry. On the other hand, the data quality fluctuates across all manufacturers. The cavity pressure curve represents the pressure inside the tool during the injection molding process over time. The shape of this curve greatly affects the quality of the produced goods. The presented approach in this project focuses on utilizing this cavity pressure curve as the only feature to predict an anomaly. Several modern machine learning anomaly detection models are introduced, evaluated and compared to a simple baseline model and the state-of-the-art method. The development of such a model strongly depends on the quality of the data. Even a non-domain expert is able to spot obvious problems with the original dataset. The labels of the original dataset contain obvious anomalies, which are labeled as normal and vice versa. Since the quality of the labels provided is not ideal, a well defined anomaly definition according to the injection molding theory has been introduced. Due to the nature of the labeling procedure of the calculated labels one could argue, that the labels have been adapted to fit the model assumptions. This is partly true, but the underlaying assumption that the cavity pressure curve of normal cavity pressure curves are very similar in nature, is backed by the known theory about the injection molding process. Therefore, the original dataset could provide a possible advantage for the existing state-of-the-art models and the calculated labels could provide a possible advantage for the molding-molly-models. Therefore, the best of both label worlds has been combined to the fusion labels to balance the benefits and to prevent a covariate shift as much as possible. All available models are then evaluated on all three label definitions and demonstrate, that it is possible to detect any significant differences in the cavity pressure curves and therefore potential anomalies. The potential of the presented approach lies in the massively reduced data volume, accessibility of the measurement variable and performance comparability with the current state-of-the-art method